用户画像平台设计
不管在任何公司,我们都需要努力了解我们的用户,以便为他们提供更优质的服务。APP内容推荐需要根据用户特征来决定推送内容;促销活动需要针对不同的用户群体设计不同的活动方案;线上产品售卖也需要了解用户喜好,才能更好地把产品卖给用户。
为了实现这些目标,我建立了一个用户画像平台。本文将首先探讨平台的功能需求和标签体系定位,然后介绍平台的架构和具体功能实现。
功能
用户画像平台主要关注分析场景,主要的使用者是公司各个业务线的运营人员和数据分析师。在平台的第一阶段,主要支持以下几个功能:
- 标签定义:标签是描述用户的一个属性,比如「使用的设备类型」、「居住地」或「年龄范围」等。
- 用户群体选择:选择一组用户标签及其相应的标签值,找出符合条件的用户群体。比如,寻找「居住在上海,且使用安卓设备」的用户。
- 用户画像:对于选定的用户群体,查看其标签分布。例如,查看「居住在上海,且使用安卓设备」的用户的年龄范围分布。
标签体系
在明确用户画像平台的使用场景和主要功能后,我们进一步回溯并确定用户标签体系。用户标签可以从两个方面进行分类:标签的实时性和标签的值类型。
首先考虑标签的实时性。由于用户画像平台的主要功能是「用户群体筛选」和「用户画像查看」,这两个功能并不需要极高的实时性,因此实时标签的优势并不明显。T+1的非实时标签完全能够满足数据分析师和运营人员的需求。
接着考虑标签的值类型,也就是标签是枚举的还是非枚举的。枚举标签,顾名思义,指的是标签值可以列举的标签,例如设备类型、网络类型、国家、城市等,这类标签在用户群体筛选中发挥了重要作用。非枚举标签则指标签值可以无限增长的标签,比如活跃天数、注册日期等,这类标签主要用于展示用户信息。考虑到「用户群体筛选」是各业务线最急迫的需求,我们在第一阶段决定不支持非枚举标签功能。
因此,我们确定了用户画像平台的第一阶段标签体系为非实时的枚举标签,主要为「用户群体筛选」和「用户画像查看」这两个查询功能服务。
架构与实现
在架构上,用户画像平台分为两个模块:数据写入,分析查询。
Roaringbitmap简介
接下来,我将简要介绍一种高效的位图压缩方法——Roaringbitmap。首先,我们来看一个问题:
假设我们有一个包含40亿个不重复且位于[0,2^32-1]范围内的整数集合,如何快速判断一个数是否在这个集合中?
如果我们直接存储这40亿个数,需要消耗约14.9GB的内存,这显然是不可接受的。因此,我们可以使用位图(bitmap)进行存储,即第0位表示数字0,第1位表示数字1,以此类推。如果一个数在原集合中,我们就将其对应的位图位设置为1,否则保持为0。这样,我们可以方便地查询结果,只需要占用512MB的内存,仅为原来的3.4%。但这种方法也存在缺点:例如,如果我们需要存储从1到5000万的5000万个连续整数,使用普通的位图仍需要消耗512MB的存储,显然,对于这种情况,我们有很大的优化空间。2016年,S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》和《Consistently faster and smaller compressed bitmaps with Roaring》中提出了Roaringbitmap,其主要特性是可以大幅度节省存储并提供快速的位图计算,因此,我们可以考虑使用它进行优化。对于前面提到的存储连续的5000万个整数,只需要几十KB。
Roaringbitmap的主要思想是:将32位无符号整数按照高16位进行分桶,即最多可能有2^16=65536个桶,论文中称之为container。
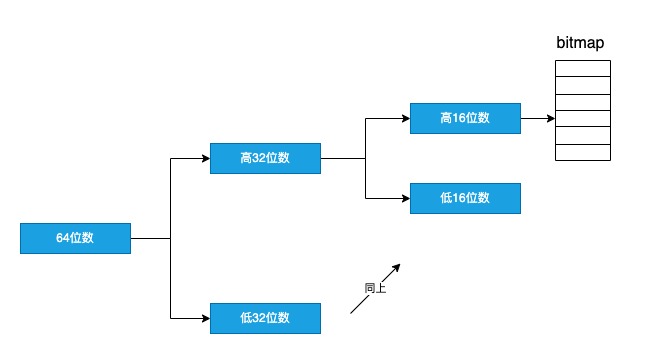
在存储数据时,根据数据的高16位找到对应的container(如果找不到,就会新建一个),然后将低16位放入container中。换句话说,一个Roaringbitmap就是许多container的集合,具体的细节可以参阅 https://roaringbitmap.org/
数据写入
我们的原始数据主要分为:
- 用户操作行为数据table_oper_raw
这包括操作时间(oper_datetime)、用户标识ID(user_id)以及用户操作行为名称(oper_name)。例如,”2024-02-24 14:31:09|o4fdG4-Tm6-SO4fz9p3fiIQoK6a0|点击首页banner” 表示在2024-02-24 14:31:09,用户o4fdG4-Tm6-SO4fz9p3fiIQoK6a0点击了首页的banner
| user_id | oper_name | oper_datetime | … |
|---|---|---|---|
| o4fdG4-Tm6-SO4fz9p3fiIQoK6a0 | click_banner | 2024-02-24 14:31:09 | … |
| o4fdG4-Tm6-SO4fz9p3fiIQoK6a0 | click_banner | 2024-02-24 14:32:20 | … |
| o4fdG4-Tm6-SO4fz9p3fiIQoK6a0 | close_game | 2024-02-24 14:44:12 | … |
| … | … | … |
- 用户属性数据table_attribute_raw
这表示用户在产品或用户画像中的属性,包含时间(datetime)、用户标识(user_id)以及各类用户属性字段(可能包括用户的新进渠道、所在地区等),例如“2024-02-24 14:31:09|o4fdG4-Tm6-SO4fz9p3fiIQoK6a0|小米商店|广东省”
| user_id | country | city | device_type | age | … |
|---|---|---|---|---|---|
| o4fdG4-Tm6-SO4fz9p3fiIQoK6a0 | China | Beijing | IOS | 10 | … |
| o4fdG4-cZVBIUGtbOYvOPDKTxXLU | China | Shanghai | Android | 5 | … |
| o4fdG479Ln6OURYtGdZIYfQHMBHg | United States | New York | Android | 12 | … |
| … | … | … | … | … | … |
然后,将大宽表的数据进行”转置”,然后批量导入到 ClickHouse,如下表所示。表中的每一行代表一个标签实例(也就是标签和标签值的组合),例如”city = Beijing”。此外,这一行还需要保存用户 id,这个 id 需要进行编码,将每个用户映射成唯一的id(32位的无符号整型),因为 Roaringbitmap 只能接受整型
| tag | tag_item | users |
|---|---|---|
| country | China | 1 |
| country | United States | 10 |
| city | Beijing | 2 |
| city | Shanghai | 1002 |
| … | … | … |
建表语句为:
1 | |
Roaringbitmap压缩
对于用户的属性/操作数据,先建一个可以存放 bitmap 的表 table_user_tag_bitmap,根据使用场景,我设计 ClickHouse 表结构如下:
1 | |
当然这里面还可以增加其他字段以区分更细的粒度,比如 app_id 等用来区分不同应用,这里简化
然后,看表包含的字段
tag代表标签,tag_item代表标签值。因为在标签的圈选查询中,经常有tag = "city" AND tag_item = "beijing"的语句,我们将(tag, tag_item)作为主键,以提高查询效率。p_day代表数据写入的日期,也作为 ClickHouse 的分片键。因为每天的标签数据都是全量导入,p_day 不仅可以用来区分标签版本,也方便我们批量删除历史数据。users用来存放根据(tag, tag_item)聚合得到用户人群
接着用聚合函数 groupBitmapState 对用户id进行压缩写入到 table_user_tag_bitmap 表
1 | |
这样原本很庞大的数据就被压缩成了几十行数据,每行包括标签和对应的用户id形成的bitmap:

数据查询
首先,简要地介绍下方案中常用的bitmap函数:
bitmapCardinality
返回一个UInt64类型的数值,表示bitmap对象的基数。用来计算不同条件下的用户数,可以粗略理解为count(distinct)bitmapAnd
为两个bitmap对象进行与操作,返回一个新的bitmap对象。可以理解为用来满足两个条件之间的and,但是参数只能是两个bitmapbitmapOr
为两个bitmap对象进行或操作,返回一个新的bitmap对象。可以理解为用来满足两个条件之间的or,但是参数也同样只能是两个bitmap。
如果是多个的情况,可以尝试使用groupBitmapMergeState,组合不同标签,圈选出用户人群。例如,我们想找出城市为北京、性别为女的用户。
我们只需首先找到城市为北京的用户人群(用 bitmap 表示),然后找到性别为女的用户人群,然后对它们进行 AND 操作即可。具体查询如下:
1 | |
结果:

其中,groupBitmapMergeState 函数对通过 WHERE 筛除得到的任意个数的 bitmap (users) 进行 AND 操作,而 bitmapAnd/bitmapOr 只能对两个 bitmap 进行操作。
查看用户画像
假如需要选取”北京的女性用户”这个人群,我们想要了解这个人群中使用设备的 benchmarkLevel。这种标签分布信息就是我们所说的用户画像。
这个查询的实现方式也是直观的。
- 使用和上一节相同的步骤,得到”北京的女性用户”这个bitmap。
- 对这个人群进行分组,分别得到各个benchmarkLevel的bitmap。我们在这一步会得到更多的bitmap。
- 将步骤2中的每一个bitmap与步骤1中的bitmap进行AND操作,就可以得到”北京的女性用户”在”设备benchmarkLevel”上的分布情况。
具体的实现方式如下查询所示。
1 | |
总结和反思
总的来看,这个方案的优势包括:
- 存储体积小,极大地节省了存储空间;
- 查询速度快,通过使用bitmapCardinality、bitmapAnd、bitmapOr等位图函数,可以快速计算用户数量和满足某些条件的查询,将耗时的join操作转变为位图之间的计算;
- 适合进行灵活天数的标签查询;
- 更新方便,用户行为数据和用户属性数据分开存储,便于后续属性的添加和数据的回滚。